
One of the ways to make the documentation better is to understand who is going to read it. This way we can optimize it, and squeeze as much valuable information as possible, without overwhelming potential readers.
A lot of engineers write documentation for themselves. In some cases it makes sense. The same engineer may make changes to the described part of the system again in a few months/years. That, however, sometimes means they make assumptions that reduce the value of the documentation.
To improve the documentation we produce, we should understand who is going to read it, before we start writing it. How can we identify the documentation audience? I prepared a few heuristics that can help us achieve that:
- Expertise level (technical and domain-related)
- Purpose
- Type of encounter
Expertise level
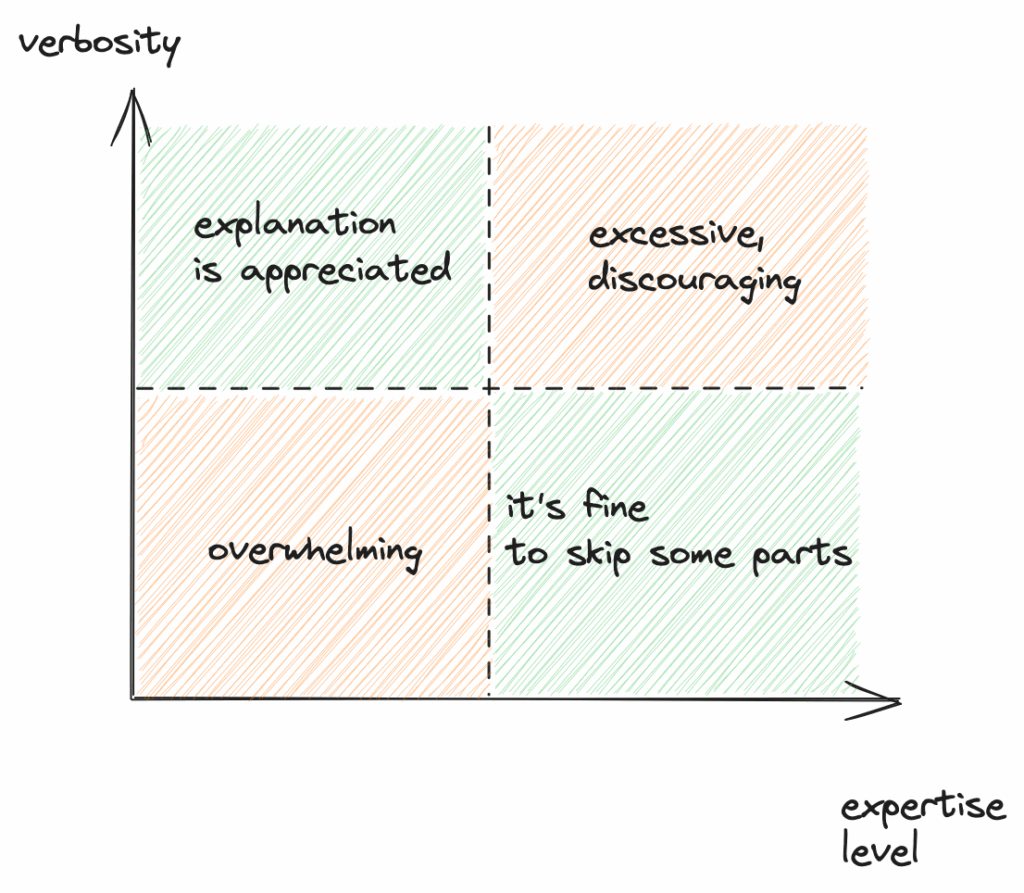
People may have different expertise levels, which may mean different things. First, let’s try to understand if people who are going to read the documents are technical or non-technical.
For engineers, we can make a few assumptions and skip some fundamental concepts. Examples could be: what is a service, class, an API, SQL Query, and so on. If the document is supposed to be read by product managers, people from marketing, or customer support, it can be easier for them if we put some explanation of basic ideas into the document.
When we talk about expertise it could be about technical skills, but also about domain knowledge. Providing too much information, and explaining every term along the way may scare off more senior engineers. Similarly, putting too much jargon (which carries a lot of meaning enclosed in a single word) into documents that are read during onboarding may be pointless, bring confusion, and overwhelm new-joiners. To be safe, we can always create glossary pages, and link them, whenever we find it necessary.
Similarly, it makes sense to create tutorials for people who are not familiar with the system. We should explain what to do, step by step. The steps should be complete and should explain the prerequisites.
Purpose
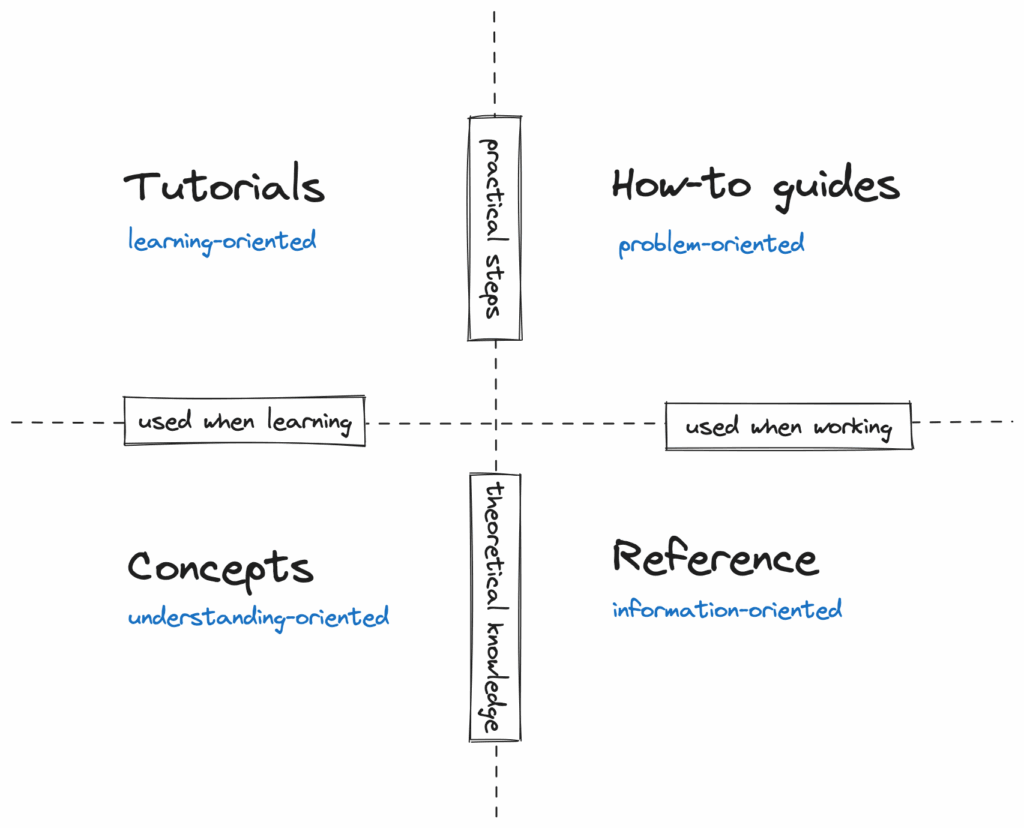
There are different types of documentation, and they have different goals. Design document has to convince decision-makers, and tutorials have to explain what to do exactly to get a feeling of what it’s like to work with the system. We can think of different document types in two dimensions:
- used when working vs learning
- practical steps vs theoretical knowledge
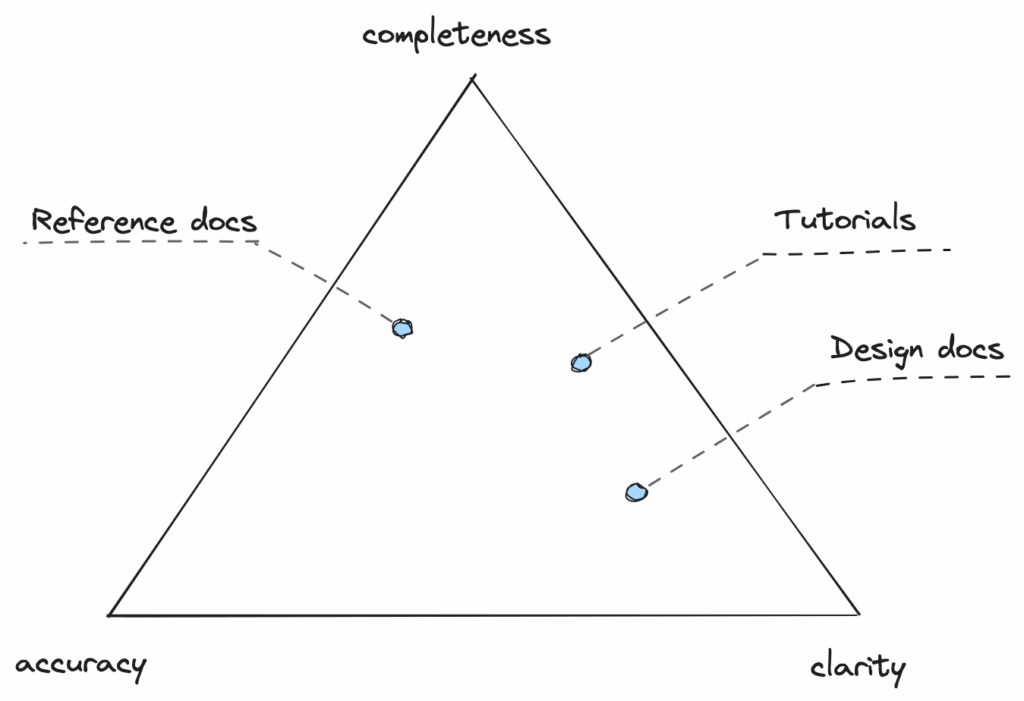
Different documents can also have different characteristics, depending on what purpose they serve. We can think of it as a triangle where each vertex means either: accuracy, clarity, or completeness. To increase one of these properties, we always need to sacrifice the others. For example, API reference has to be complete and accurate – because of that, it loses clarity. Similarly, the high-level design has to be clear to convey the message quickly, but it doesn’t have to be complete.
I found two tips that can help us identify the purpose of the document easier:
- create an outline in advance, before you start writing – highlight the most important points – that make the document more structured and focused.
- introduce the tl;dr; section – explain what you can find in the document (and optionally what you won’t find). It helps when people stumble across the document.
Speaking of which, the third heuristic:
Type of encounter
Try to think about how people find and open your documents. We can split them into two groups
- Seekers
- Stumblers
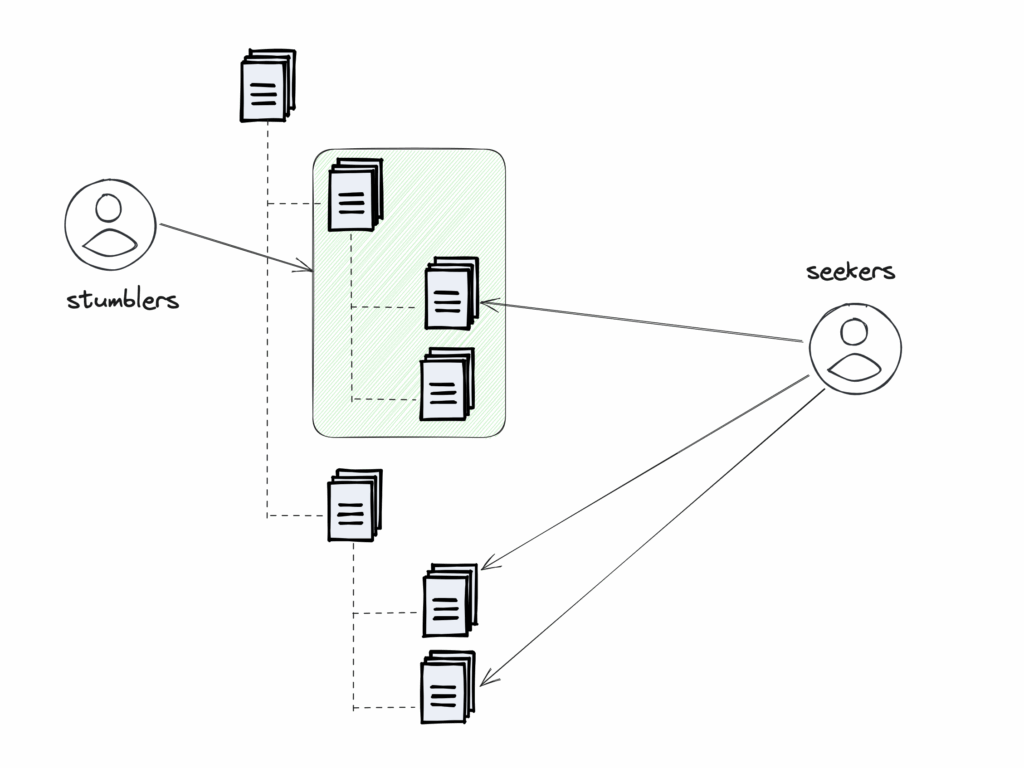
Seekers are people who have a very specific problem to solve. They rely on the search functionality a lot. They view documents as single records returned, without a structure.
To satisfy these users, we can think of it as improving SEO for internal documents. I often use different phrasing for similar terms, to increase the findability surface. Additionally, I try to think – “if I wanted to solve a problem related to this area – how would I ask the question?” and then I include similar questions in the document.
Stumblers don’t know exactly what they’re looking for yet, and they’re exploring ideas to understand the problem space better. In this case, there are a few ideas that can help:
- an additional dimension of grouping – for example, tagging. We may have a marketing space that documents different aspects and use cases, and one of these is an integration with a certain tool. But that tool is sometimes used in other fields. Therefore we may have a separate landing page about the tool that aggregates document pages about it in a different context. And similarly a landing page for the team that does the same with topics that are relevant to them.
- linking pages – instead of explaining the same concepts multiple times we can explain it once, and link it. With this approach, the page stays up-to-date longer. It’s a concept inspired by the Zettlekasten method for note systems.
Takeaways
In the article, we saw that we can write better documentation by optimizing it for its audience – especially in cases when different people read and write the documents.
To identify the documentation audience we used three heuristics:
- expertise level – both technical and domain-related – it helps us determine wording choice, whether we should bring more details, or we could use jargon.
- purpose – different document types have different characteristics. If we understand them, we can make the documentation more focused and structured
- a type of encounter – people can find the document in different ways
- they might have been looking for a very specific problem to solve – these are seekers
- or they wanted to first explore ideas to build a big-picture – they are called stumblers.
Sources
- https://documentation.divio.com/
- http://www.nickmilton.com/2023/03/the-value-of-jargon-in-km-50-words-for.html
- Manshreck, T., Winters, T., Wright, H., Software Engineering at Google, O’Reilly Media, Inc, 2020



