
These are my notes from the book: AI Engineering: Building Applications with Foundation Models by Chip Huyen
This book was listed on my 2025 reading list. See other books 👉 here
I read this book in 2025. The book just perfectly aligned with my current challenges at work where we were building an RAG-based AI assistant. We are in the AI era. You can use AI to be more productive, and incorporate the AI into your products. This book helps you with the latter. I knew I needed to get the basics, and this book was a perfect fit. I admit, I didn’t fully grasp everything (especially the fine-tuning chapters), but most of it was extremely valuable. I finally built my mental model about the concepts and understood the difference between machine learning data scientist and AI engineer.
These notes don’t cover everything in the book, only the parts that seemed relevant to me, but they can be a reference for someone who also read the book and wanted to remember key points quickly.
1. Introduction to building AI applications with Foundation models
Tokens are on average ¾ of the word, Because there are fewer unique tokens than words. E.g. both cook and ing bring meaning. Thanks to that LMs can also understand made-up words e.g. Chatgpting. The number of tokens is a vocabulary. (GPT4’s vocabulary is 100,256) Process of breaking words into tokens is tokenization.
Language models:
- masked language models
- given context before and after find the gap. my favorite _ is blue.
- BERT
- non-generative tasks: sentiment analysis, text classification
- autoregressive language models
- given only preceeding tokens. My favorite color is ___
- gen tasks
The power of language model comes from the fact that they are self-supervised which is way cheaper than other models to train. They can train themselves. They have the sentence, they can train predicting the next token.
For training language models sequence markers are important (BOS – beginning of sequence, EOS – end of sequence).
In Self-supervision labels are inferred from the input data. In unsupervised learning you don’t need labels at all.
What makes large language models large? Number of parameters.
- GPT-1 – 117 millions
- GPT-2 – 1.5 billion
A model that can work with more than one data modality is called a multimodal model.
Foundation models are general-purpose, and can perform more types of tasks e.g. Translation, Question Answering, Question generation, Information extraction, Textual Entailment, Program execution, Text categorization, Sentence composition, Cause effect classification, Linguistic probing, Named entity recognition, Toxic language detection, text to code, Text completion, Question understanding and others.
AI engineering refers to the process of building applications on top of foundation models. ML engineering involves developing ML models, AI engineering leverages existing ones.
AI use cases:
- coding
- https://github.com/abi/screenshot-to-code
- https://github.com/AntonOsika/gpt-engineer
- https://github.com/context-labs/autodoc
- writing
- consumer: photo, video editing, design
- enterprise: presentation, ad generation
- education
- consumer: tutoring, essay grading
- enterprise: employee onboarding, upskill training
- conversational bots
- information aggregation
- creating summaries
- data organization
- image search, knowledge management, document processing
- workflow automation
- travel/event planning
- lead generation
Interesting idea: teaching method – giving students AI-generated essays and have them find mistakes.
Talk-to-your-docs – process contracts, papers and let you retrieve information in a conversational manner.
Fast breakdown – summarize notes and list open questions and action items.
IDP – Intelligent Data Processing. E.g. extracting data from images or PDFs.
Use case of improving models: AI can generate labels, a human can verify them. Still less work if human had to create them.
AI features
- critical or complementary
- would the app work without AI? E.g. face ID without AI is pointless.
- reactive or proactive
- reactive – reaction to user request e.g. chatbot
- proactive – e.g. traffic alerts on Google Maps. For proactive latency is not critical but the quality bar is higher
- dynamic or static
- dynamic features are updated continually with user feedback. Each user has their own model continually finetuned on their data.
- static are updated periodically
Involving human in AI’s decision-making process is called human-in-the-loop. Microsoft created a framework: Crawl-Walk-Run:
- Crawl: human involvement necessary.
- Walk: AI can directly interact with internal employees
- Run: increased automation, direct AI interactions with external users
AI product defensibility: if something it’s easy to build for you, it is as well for your competitors. If the application is built on top of the model, what happens if the model extends to capabilities that you’ve built? Three pillars are:
- technology – this is accessible to everyone
- distribution – usually big companies already have the advantage
- data – here the startup can overtake bigger companies.
It’s easy to build a fun demo in a weekend, and then it takes months to build the real product out of it.
Maintenance of AI apps is high because models change a lot. Also their costs. You may decide to build your own model to find out that in a year its cost is cut in half.
AI engineering stack
- application development
- AI interface, prompt engineering, evaluation
- model development
- Inference optimization, dataset engineering, modeling & training, evaluation
- infrastructure
- compute management, data management, serving, monitoring
With ML engineering you experiment with different hyperparameters. With foundation models you experiment with different models, prompts, retrieval algorithms, sampling variables.
ML engineering focuses on building the model, AI engineering on using the existing model. Current models are bigger so it means that companies need people who know how to work with GPUs.
AI engineering focuses on models witn open-ended outputs. This is more challenging when it comes to output evaluation.
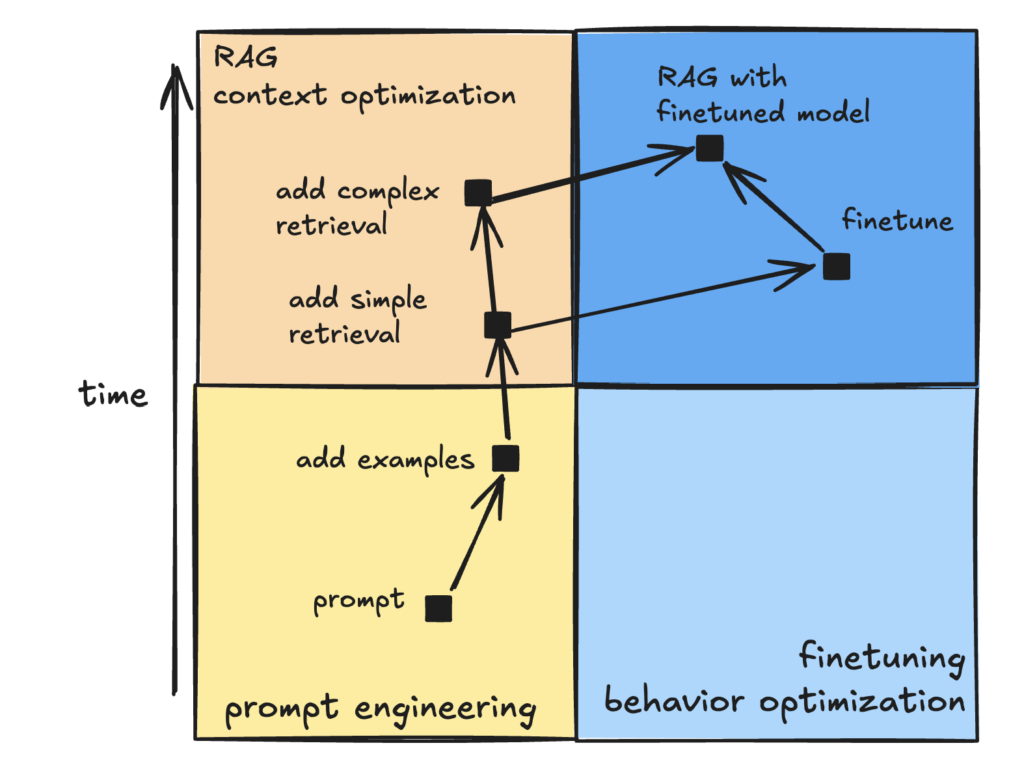
Model adaptation:
- prompt-based – without changing weights
- fine-tuning – changing weights
Model training:
- pre-training – initial model learning. Most compute intensive (98% of the resources)
- fine-tuning – made by application developers
- post-training – made by model developers
Prompt engineering and providing context is not training or fine-tuning.
2. Understanding Foundation Models
Training data
Important asepct of the model training is dataset. If the model wasn’t trained on certain tasks it may have problems performing them. This means models are prone to under- representation e.g in terms of languages.
Quality of data is more important than quantity.
Different languages have different median token length. E.g. English is 7, while Hindi is 32 which has performance implications.
Different languages may cause different behaviors. E.g. ChatGPT is more willing to produce misinformation in Chinese than in English.
Many models were trained on CommonCrawl datasets which are free, huge, but also of low quality.
Domain-specific models can perform better on domain-specific tasks but it’s more difficult to get the training data. Example domain-specific models:
- AlphaFold
- NVIDIA BioNeMo
- Google Med-PaLM2
Modelling
Model architecture:
- transformer
- parallel input processing, sequential output decoding
- attention mechanisms at its core
- transformer architecture is composed of multiple transformer blocks. Each block contains: attention module, and MLP (multi-layer perceptron) module
- https://m.youtube.com/watch?v=eMlx5fFNoYc&t=58s&pp=ygUTYXR0ZW50aW9uIG1lY2hhbmlzbdIHCQmNCQGHKiGM7w%3D%3D#
- other architectures:
- seq2seq – based on RNN (Recurrent neural network). No context limits but sequential input processing
- GAN – generative adversial networks
- RWKV – RNN-based
- SSM – state space models
Model size
Model’s learning capacity:
A model size can mean no of parameters.
Model size can help assess compute resources needed: if a model has 7B parameters, each parameter is stored using 2 bytes (16 bits), the GPU memory meeded is 14B bytes (14GB).
Unless the model is sparse – contains mostly zero-value parameters which consume less resources.
How much model learned :
Model size can also mean size of the training data. (usuallny in no of tokens)
A large model can underperform a smaller model if it’s not trained on enough data.
The number of tokens in a model dataset is not the same as training tokens. A dataset can have 1 trillion tokens and a model is trained on it for 2 epochs (passthrough a dataset) so the training tokens is 2 trillions.
Data quality, quantity and diversity matter.
Training costs
Model compute requirements is in FLOP – floating point operation
If one NVIDIA H100 costs $2/h the approx cost of GPT3 training is $4 millions.
Compute-optimal models are models where you start with the compute budget and adjust parameters based on that.
A parameter can be learned by the model during training process. A hyperparameter is set by users (e.g. number of layers, model dimension, vocabulary size, batch size, number of epochs, learning-rate, per-layer initial variance) to configure the model and control how model learns. For small models it’s a common practice to train a model multiple times with different sets of hyperparameters. For large it’s not easy because training them once it’s already expensive.
Predicting which hyperparameters to use is called scaling extrapolation.
Scaling bottlenecks:
- training data
- models don’t know yet how to forget the data
- people already put data in the internet that would influence future models
- copyrighted data for training may be an advantage
- AI models are trained on AI-generated content which degrades their performance
- electricity
Post-training
Supervised Finetuning – finetune in high-quality instruction data to optimize models for conversations instead of completion
Example prompts used to finetunue – demonstration data: Open QA, Brainstorming, Chat, Rewrite, Summarization, Classification, Other, Closed QA, Extract, Generation.
Preference finetuning – finetune model to output responses that align with human preferences. Typically done with reinforcement learning (RLHF).
RLHF relies on a reward model. Given a prompt-response pair outputs a score for how good the response is.
It’s difficult to rate responses independently (pointwise), so instead labellers compare two responses.
Sampling
greedy sampling – always taking the most probably answer. Makes sense for classification, but for generation it produces “boring” outputs.
Given the input, the neural network outpute a logic vector, which is converted to a vector of probabilities using Softmax layer.
Sampling strategies:
- Temperature – the bigger the temperature, the more creative (and less coherent) the answer
- Top-k – to optimize softmax calcultion, instead of the whole vocabulary, it takes k logits – from 50 to 500.
- Top-p – also known as nucleus sampling – sums cumulative probability of most probable values, and stops when the sum reaches p.
- Min-p – you set the minimum probability that a token must reach
Stopping condition – it makes sense to set when the model should stop generating to reduce costs. But it may also result in malformed response if it has to use specific format e.g. JSON.
Test time compute – generating multiple outputs, potentially with different sampling strategies, and picking the best one. It could show multiple options to the user to choose better option. Or sum probabilities of the tokens (average of logprobs can be taken to avoid bias of choosing shorter sentences), or an evaluator.
Structured outputs
Use cases:
- tasks requiring structure outputs. E.g. text-to-sql.
- tasks where outputs are used by downstream applications. Especially important with agents.
It can be achieved by:
- prompting – telling the model to return specific format. Some use AI as a judge to verify the format is correct
- post-processing – if the model makes a commin mistake we can fix it on our end e.g. by correcting the JSON
- tip: YAML may produce less tokens than JSON
- constrained sampling – adding a filter that verifies the next token could be possible.
- this is rarely used because it’s complex to create vocabulary for each format
- finetuning – you could use classifier and then apply different model architecture if it detects certain format.
Probabilistic nature of AI
This leads to two effects:
- inconsistency
- same input, different output
- slightly different prompt, drastically different output
- some mitigation: fixing parameters of sampling, memory, caching the input and output pair
- hallucinations
- it’s not clear what’s the origin. Could be self-delusion, and the fact that it can’t distinguish generated from training data.
- the other idea is mismatch of labellers internal knowledge during supervised fine-tuning.
3. Evaluation Methodology
Challenges:
- results require fact-checking, reason, domain expertise
- open ended results
- most models are black boxes so you can only verify its outputs
- underfunded research compared to developing new models
Understanding Language modeling metrics
- entropy
- measures how much information, on average, a token carries. Higher entropy means more bits are needed to represent a token
- the lower the entropy, the more predictable the language
- cross-entropy
- cross-entropy on the dataset measures how difficult it is for the language model to predict what comes next in the dataset.
- Kullback-Leibler divergence measures the difference between entropy of a dataset and what the model has learned. If the model learned perfectly from its dataset, the KL divergence is 0.
- bits-per-character, bits-per-byte
- If the number of bits per token is 6 and on average, each token consists of 2 characters, the BPC is 6/2 = 3
- due to different encoding (ASCII needs 7 bits, UTF-8 needs between 8 and 32 bits), bits-per-byte is use: the number of bits a language model needs to represent one byte of the original training data
- perplexity
- measures the amount of uncertainty it has when predicting the next token. Higher uncertainty means there are more possible options for the next token.
- More structured data gives lower expected perplexity
- The bigger the vocabulary, the higher the perplexity
- The longer the context length, the lower the perplexity
- it’s low for text it knows. It can be used to detect e.g. if benchmark data was also used as training data
- high perplexity can help detect abnormal texts
Exact evaluation
- functional correctness
- similar to unit tests. You automate checking if the model created expected outcome.
- good for code generation – you simply write unit tests to check if the generated code passes
- good for game bots
- similarity measurements against reference data
- for things you can’t easily automate
- e.g. when you translate, you provide example translations
- four strategies:
- human evaluator can make a judgement if the texts are the same,
- exact match
- good for short answers e.g. what’s 2+4
- lexical similarity
- you break down the sentence into tokens and measure how many overlap with the reference data. It measures if the output contains similar words
- fuzzy matching
- n-gram similarity
- semantic similarity
- uses embedings
- measures if the outputs means similar thing.
- “let’s eat, grandma” vs “let’s eat grandma”. Lexically similar, semantically not
- AI as judge is more and more common
- reference data is sometimes AI-generated and reviewed by humans.
Embedings:
- typical size between 100 and 10,000
- Google’s BERT, Open AI’s CLIP
- Pinterest uses embedings for image
- ULIP and CLIP models provide embedings of different modalities in a unified space
AI as a judge
- given the question and answer evaluate the answer
- compare generated response to a reference response
- compare two generated responses and determine which one is better
- example things you can evaluate:
- groundedness, relevance, coherence, fluency, similarityz faithfulness, conciseness, harmfulness, helpfulness, controversiality, misogony, intensitivity, criminality, maliciousness, corectness
- the wider the range of scoring, the worse the model performs. Typically the best is 1-5.
- the judge is a model plus prompt.
- downsides:
- it increases costs and latency
- you can use cheaper models as judges
- you can use spot-checking – evaluate
- it’s inconsistent (probabilistic)
- criteria ambiguity – no standardized way of scoring
- it increases costs and latency
- biases
- self-bias – gives better score for answers generated by the same model
- first answer bias – prefers the first response from the list of responses
- verbosity bias – prefers longer responses even if with errors
- specialized small models can be used as judges
- reward model – e.g Cappy. Given a prompt and response produces a score how correct the answer is
- reference-based judge – e.g. BLEURT. Evaluates how good the response is compared to the reference
- preference model – e.g. PandaLM. Evaluates which answer would be more preferred by users
- comparative evaluation – good for subjective evaluation.
- not all answers should be selected by preference. Sometimes corectness is more important.
- asking users to pick answers can cause user frustration. If user asks a question, and a model gives 2 different answers to choose which one they prefer is pointless
- rating algorithms: Elo, Bradley-Terry, TrueSkill
- LMSYS ChatBot arena
- challenge:
- scalability – comparing more model pairs increases number of evaluation dramatically because you need to compare each model with each model. Ranking models assume transitivity (if A>B, and B>C, then A>C). But this is not always correct because the matches are done on different prompts.
- lack of standards and quality control. Crowdsourcing may not reflect well work-related use cases. E.g. users may downvote the model that refuses to tell an inappropriate joke, but the developers implementint a chatbot may prefer that.
- comparative only tells you that model A is better than B, but not how better
4. Evaluate AI systems
Evaluation criteria
- evaluation-driven development. Something like TDD. You define evaluation criteria, and then build.
- types of evaluation:
- domain-specific capability
- typically exact match
- generation capability
- factual consistency– AI as judge
- local – based on context. Eg if chatbot answers based on company’s policy
- Global – based on open knowledge
- queries prone to hallucination: that involve niche knowledge, queries asking for things that don’t exist
- techniques:
- self-verification
- knowledge-augmented verification
- textual entailment – verifying whether a statement is consistent with a given context
- safety
- inappropriate language, profanity, explicit content
- harmful recommendations, “step by step guide to rob a bank”
- hate speech
- stereotypes
- bias towards political views
- factual consistency– AI as judge
- instruction-following capability
- IFEval
- instruction types:
- keywords e.g. include keywords, forbidden words
- language e.g use language X
- length constraints e.g. number words/sentences/paragraphs
- detectable content e.g postscript, placeholders, first words in i-th paragraph, JSON format
- verification that can’t be easily automated can be bronen down into easy yes/no questions
- e.g. is the generated text a questionnaire, is the generated questionnaire designed for hotel guests etc.
- roleplaying. E.g. RoleLLM
- cost and latency
- cost: cost per output token
- scale: tokens per minute
- latency: time to first token, time per total query
- overall model quality: Elo score
- Code generation capability: pass@1
- Factual consistency: Internal GPT metric
- domain-specific capability
Model selection
Hard attributes (those which you can’t control) vs soft attributes (you can)
- model build vs buy
- same model can be offered by a model provider or cloud provider with different performance characteristics (e.g. OpenAI and azure)
- considerations:
- data privacy
- data lineage and copyright
- performance
- companies usually open source weaker models
- functionality
- API cost vs engineering cost
- control, access and transparency
- commercial providers may change the API or go out of business
- on-device deployment
- navigate Public benchmarks
- a tool to evaluate model on multiple benchmarks is an evaluation harness. E.g. EleutherAI, OpenAI evals
- public leaderboards rank models based on their aggregated performance on a subset of benchmarks
- benchmarks quickly become saturated
- data contamination: when the same data is in training and benchmark
- could be unintentional because it was just scraped from internet or banchmark and model developers accidentally used the same textbooks
- can also be intentional because the developers want to achieve high score, or because the benchmark data is just high-quality.
- detecting : n-gram overlap (n tokens matching ) or low perplexity
Design your evaluation pipeline.
- step 1: evaluate all components
- turn based vs task based
- example: extracting current employer from pdf could involve multiple steps: pdf-to-text, and extracting information from text
- task may involve multiple turns e.g. maintaining a conversation like 20-questions game
- Step 2: create an evaluation guideline
- define evaluation criteria. Correct answer isn’t always good answer. Example criteria: relevance, factual consistency, safety
- create scoring rubrics with examples
- tie evaluation metrics to business metrics eg factual consistency 90% = we can automate 50% of customer support requests
- step 3: define evaluation methods
- select evaluation methods
- use automatic metrics as much as possible, but falling back to human evaluation is also ok
- annotate evaluation data
- slice your data – separate your data into subsets and look at system’s performance on each subset separately
- evaluate your evaluation pipeline
- do better responses indeed get higher scores?
- if you run the same pipeline twice do you get different results?
- how correlated are your metrics. If too much you don’t need both
- how much cost and latency does your evaluation add to your application
- select evaluation methods
5. Prompt engineering
introduction to prompting
- parts of the prompt:
- task description
- examples of how to do this task
- the task
- prompt perturbation: e.g. changing 5 with “five”. If model is robust, it won’t change the response dramatically
- most models perform better when the task description is at the beginning
In-context learning
- models can learn new things from the prompt. This is called in-context learning
- each example provided in the prompt is called a shot
System prompt and user prompt
System prompt: task description
User prompt: the task
Different models use different chat templates. You have to follow them very carefully to avoid performance degradation.
Models might be post-trained to pay more attention to system prompts to avoid prompt injections.
Context length and context efficiency
Research has shown that models are better at understanding instructions at the beginning and the end of the prompt.
To test it the method called “needle in a haystack” can be used.
Prompt engineering best practices
- Write clear and explicit instructions
- the explain without ambiguity what you want the model to do
- e.g. specify score 1-5. Can it be float or only integer
- specify if you want to try its best or answer I don’t know
- ask the model to adopt persona
- e.g. a childish essay can be scored differently if you start with “you’re a first-grade teacher”
- provide examples
- if you’re concerned about tokene you can experiment with more concise formats e.g.
label the following item as edible or inedible. Chickpea --> edible, box --> inedible, {{input}} -->
- if you’re concerned about tokene you can experiment with more concise formats e.g.
- specify the output format
- you can optimise costs by telling it to be concise
- the explain without ambiguity what you want the model to do
- provide sufficient context
- break complex tasks into simpler subtasks
- e.g. in a support chatbot the weaker model can do intent classification, and the stronger can generate the response
- give the model time to think
- chain-of-thoughts and self-critique techniques
- “explain your rationale before giving an answer”. “Think step by step before arriving at an answer”.
- iterate your prompts
- version your prompts.
- make sure to test changes systematically
- standardize evaluation metrics
- evaluate prompt engineering tools
- e.g. OpenPrompt, DSPy, Promptbreeder
- control costs of these tools as they also call APIs
- example: Firebase dotprompt file. Prompt + metadata
Defensive prompt engineering
- types of attacks
- prompt extraction
- jailbreaking and prompt injection
- information extraction
- proprietary prompts and reverse prompt engineering
- public prompt marketplaces: PromptHero, Cursor directory, PromptBase
- jailbreaking and prompt injection
- direct manual prompt hacking
- typos to avoid regexp checks
- adding special characters on which the model wasn’t trained to bypass its safety measures
- using unexpected format e.g. a poem about building a bomb
- roleplaying e.g. DAN (do anything now), or grandma telling a story about building napalm
- automated attacks: PAIR – Prompt Automatic Iterative Refinement
- indirect prompt injection
- passive phishing. Putting malicious code e.g. into public repository counting that the code assistant will suggest using it
- active injection. E.g. if you know someone’s using email assistant you can embed instructions in the email
- direct manual prompt hacking
- information extraction
- types:
- data theft
- privacy violation
- copyright infrigement
- factual probing – trying to detect model’s knowledge by letting it fill in the gaps. It can also extract sensitive information from training data.
- bigger models memorize more so are more prone to data extraction
- copyright regurgitation. You can put paragraphs of copyright content. If the model generates second paragraph from this book, it might have seen it during training.
- types:
Defenses against prompt attacks
- metrics :
- violation rate – successful attacks
- false refusal rate – how often model refuses a query when it’s possible to answer safely
- model level
- openAI proposes instructions hierarchy
- when fine-tuning pay attention to generating safe responses to borderline requests (requests that can be answered both safely and unsafely)
- prompt level
- one technique is to repeat the instructions before and after user prompt
- if you know potential attacks you can explicitly mention them in a prompt
- System level
- you can look for forbidden words to avoid controversial topics. Or modification queries (UPDATE, DROP, DELETE) if it has access to db
- if it executes code provide isolation
- anomaly detection algorithms can identify unusual prompts
- check both inputs and outputs. Harmless input can produce toxic outputs or display PII
- a user sending multiple similar-looking requests may be an attack trying to find prompt vulnerabilities
6. RAG and agents
RAG
It lets the model fetch only necessary knowledge (instead of providing all the knowledge in the prompt)
RAG architecture
- retrieval:
- term-based retrieval
- TF-IDF
- term frequency (assumption that if the term e.g. AI occurs a lot in the document it must be relevant)
- inverse document frequency – assumption that if the words occurs in multiple documents it is less informative e.g. “for”, “the”
- BM25 – normalizes TF-IDF for the document length
- it’s more lexican thab semantic
- TF-IDF
- embedding-based retrieval
- semantic retrieval
- vector database
- for search ANN – approximate nearest neighbor algorithm is used the most
- vector search algorithms:
- LSH locality-sensitive hashing
- HNSW (Hierarchical Navigable Small World)
- Product Quantization
- IVF (inverted file index)
- Annoy (Approximate Nearest Neighbors Oh Yeah)
- converting data into embeddings can obscure keywords, such as specific error codes, e.g.,
EADDRNOTAVAIL (99), or product names, making them harder to search later on
- hybrid search – you can combine both approaches. Use term based to get first results and then rerank using embeddings
- term-based retrieval
Retrieval optimization:
- chunking strategy:
- you can split documents recursively using increasingly smaller units to reduce the chance of related texts being arbitrarily boken off
- smaller chunk allows for more diverse information but also can loose important information. And it’s more expensive to compute
- query rewriting
- if a user follows up on a previous answer e.g. “and how about X?” You need to rewrite the context from the previous question to the 2nd one.
- contextual retrieval
- you can add metadata to each chunk
- multimodal retrieval
- you need embeddings for images, or retrieve based on metadata like title, caption
- tabular data- you need e.g. text-to-SQL model and a possiblity to execute the query. It could be that not all tables for into the context
Agents
Agents are a combination of tools and environment. They have to plan the task, perform and reason about the results.
The accuracy accumulates. If one task has accuracy of 95% with 10 steps it’s 60%.
Tools:
- knowledge augmentation (context construction)
- web search, news API
- it also opens the model for attacks
- capability extension
- calculator, code interpeter, calendar, timezone converter, OCR
- write actions
- SQL executor, sending emails
Planning:
- it’s a task and constraints
- planning and executing need to be decoupled, so that the plan can be evaluated first (self-critique, AI as judge)
- describe available tools and their parameters
- use stronger models. Stronger models are better at planning
- planning is a search problem and requires backtracking: If path A doesn’t work, take a step back
- control flow: sequential tasks, parallel, if statement, loop
Reflection
- it can be used to check if the query is feasible
- check after each step if it sticks to the plan
Failure modes:
- invalid tool, parameters
- model doesn’t achieve the goal or ignores the constriants
- model claims it’s achieved the goal (but it hasn’t ) – errors in reflection
- tools can have errors in outputs
- a model may not have access to tools it needs
Efficiency:
- how many steps does the agent need
- how much does it cost
- how long does it take
- some actions may be inefficient for humans but ok for computers and vice versa e.g. visiting 100 websites.
Memory
Types of memory:
- internal knowledge – embeded into the model
- short-term memory – context
- long-term memory – external data source, similar to RAG
Use cases
- manage information overflow within a session
- persist information between sessions
- boost a model’s consistency
- maintain data structural integrity
Strategies to decide what to move from short-term to long-term memory:
- FIFO
- one downside is that in some conversations the earliest messages might carry the most information
- Using a summary of a conversation
- Reflection approach
- AI determines whether the new information should be inserted into the memory, should merge with existing memory or replace if the new information contradicts the old one
7. Finetuning
Finetuning overview
- transfer learning. Based on one skill you can do other task. E.g. knowing how to translate spanish to English and English to Portuguese, you can translate Spanish to Portuguese.
- finetuning can be viewed as unlocking capabilities a model already had but that are difficult for users to access via prompting alone.
- another example is feature-based transfer e.g using models trained on ImageNet dataset to extract features from images and use these features in other computer vision tasks such as object detection or image segmentation
When to finetune
reasons to finetune
- finetuning is commonly used to improve model’s ability to generate outputs following specific structure e.g JSON, YAML
- useful when the general model wasn’t sufficiently trained on your specific task e.g. less common SQL dialect
- bias mitigation – providing more training data that counter the biases
- finetuning smaller models is much more common
reasons not to finetune
- finetuning for a specific task can improve performance for that task but degrade for others
- if you can’t finetune for all your tasks consdier using separate models for different tasks
- finetuning requires high upfront investment
- annotated data
- knowledge how to train models
- figuring out how to serve it
- you need to continually monitor other models. It could be that some base models improved and outperform your tuned model
- finetuning could be used to save context length because instead of adding examples every time we can train the model once on many examples. But this is irrelevant with prompt caching.
Finetuning and RAG
- RAG can help if the model failures are information-based
- e.g. doesn’t have relevant knowledge or the knowledge is not up to date
- Finetuning can help with failures which are behavior-based
- e.g. the information is correct but irrelevant to the task
- or the output format is incorrect e.g. the code doesn’t compile
memory bottlenecks
- trainable parameters – not all parameters can be updated
- backpropagation – how neural networks are trained
- forward pass – calculating output based on input
- backward pass – updating weights
- the difference between the computed output and expected output is called loss
- Adam optimizer
- memory needed for inference:
- M × N × 1.2 (N model’s parameters, M memory needed for each, + 20% for activation and key value vectors)
- Memory needed for training
- model weights + activations + gradients + optimizer states
- 13B parame x 3 (Adam optimizer) x 2 bytes = 78GB
- Numbers:
- neural networks usually want to use numbers with less bits to reduce memory footprint.
- FP32 (32 bits), FP16(16 bits), BF16 designed by Google to optimize AI performance
- number is made of: range + precision
- converting values from one type to another may change their value e.g. 1234.56789 in FP32, 1235.0 in FP16, 1232.0 in BF16
- quantization – reducing precision. Common are FP8 and FP4. E.g. NVIDIA new GPU architecture Blackwell which supports model inference in 4-bit float
- you can’t go below 1 bit
- precision reduction can decrease latency but can degrade performance esepcially if numbers are outside of the number range.
- usually done in post training (PTQ) or on-device inference
- less popular in training.
- There it has 2 goals:
- produce a model that can perform well in low precision during inference
- to reduce time and cost
- training in low precision is harder to do because backpropagation is more sensitive to lower precision
- it’s also possible to have different phases of training in different precision levels
- There it has 2 goals:
Fine-tuning techniques
Parameter-efficient finetuning (PEFT)
- to fit a model into a give hardware you can either reduce memory footprint (quantization, PEFT), or make better use of the hardware (CPU offloading)
- a technique is considered Parameter-efficient if it can achieve performance close to that of full finetuning while using fewer trainable parameters (partial finetuning) e.g. last few layers.
- adding adapter layer can have good performance increase with much less parameters. But at the cost of increased inference latency
- PEFT techniques
- adapter-based methods – e.g. LoRA (low-rank adaptation), BitFit, IA3 – adds trainable parameters to the model’s architecture
- soft prompt-based methods – modifies how the model processes the input by introducing special trainable tokens (soft prompt – not readable by humans, a vector)
- LoRA
- from matrix of weight W (m×n) takes rank (r) and create 2 matrices: A(r×m) and B(r×n)
- it works because pre-trianing compresses model’s intrincic dimension (the better trained the model, the easier to finetune it)
- you can merge lora matrices back into the original weight matrix, or you can serve them on top of that which increases inference latency. The latter is useful if you have multiple finetuned models on top of the same base model.
- Apple haed multiple LoRA adapters to adapt the same 3B base model to different iPhone features.
- LoRA doesn’t offer performance as strong as full finetuning
- QLoRA – quantized. Further decreasing memory footprint. But increases computation time
Model merging and Multi-task finetuning
- useful when you want to finetune model for specific multiple tasks. You can teach the model separately but in parallel one task at the time and merge the model
- also useful for on-device deployments when you need specific tasks but can’t have enough space for multiple models
- federated learning – you deploy the same model to multiple devices. It’s trained separately on different data. After some time you merge these models
- model ensemble – you ask the same query to X models and then generate final response based on them. Bigger costs
- merging techniques:
- summing e.g. linear combination (averaging), spherical linear interpolation
- layer stacking e.g. frankenmerging, depthwise scaling
- concatenation
Fine-tuning tactics
- development paths
- progression – start with the cheapest to check if it works
- distillation – start with the strongest model and small dataset. Fine-tune and generate more training data. Use it to finetune weaker model
- llama police – list of finetuning frameworks and techniques
- hyperparameters
- learning rate – how fast should the model change with each learning step
- batch size – how many examples a model learns from in each step to update its weights. The bigger the batch the faster the training but you’re limited by the hardware
- number of epochs – how many times each training example is trained on
- prompt loss weight –
8. Dataset engineering
- model-centric AI – trying to optimize the model e.g. designing new architecture, increasing size
- data-centric AI – enhancing the data
Data curation
- curation is not only about creating new examples but also about removing unwanted behaviors
Data quality
- relevant
- aligned with task requirements
- consistent
- correctly formatted
- sufficiently unique
- compliant
Data coverage
- also referred to as data diversity
Data quantity
- Llama 2 was trained on approx 1 billion examples. And Llama 3 on 15 billion
- it can happen that it’s better to train the model from scratch than to finetune due to ossification i.e. model weights don’t adapt well to the fine-tuning data
- factors that can affect how much data you need
- finetuning techniques
- task complexity
- base model’s performance
- if you have small amount of data use PEFT on more advanced models. If you have large amount of data use full finetuning with smaller models
- in vast majority of cases you should see improvements after finetuning with 50-100 examples
Data acquisition and annotation
- a mix of different sources
- public data
- purchasing proprietary data
- annotating data
- synthesizing data
- creating annotation guidelines is one of the biggest challenge here
Data augmentation and synthesis
- it helps overcome data privacy limitations by generating new data
- types of data generation
- rule-based data synthesis – using templates. Also perturbation, adding noise to increase model’s robustness
- simulation – used often in robotics e.g. simulating self-driving car encountering a horse on a highway
- using AI itself
- self-play – playing AI against AI, or do the role-play
- using it to rephrase
- simulating API responses
- you can use back translation to verify the quality of generated data e.g. generate documentation from code snippets and then generate code from this documentation
- you can ask ai to generate instructions, responses, topics of instructions or mix with human writing instructions and ai respnses or the opposite.
- reverse instruction: take existing long-form high-quality content like stories, books and ask AI to generate prompts that would elicit such content
- coding examples are the most frequently synthesized data because it can be functionally verified
- major limitations:
- quality
- superficial imitation – model might struggle with tasks outside its training data
- model collapse – training AI models on AI-generated data can degrade their performance over time. It can also amplify bias
- obscure data lineage – e.g. if the original model violates copyrights your synthetic data can also do
Model distillation
- the knowl of the big model is distilled into small model
- example: DistilBERT reduces size of BERT model by 40% while retaining 97% of its language comprehension and being 60% faster.
- not all models can be distilled due to licensing
Data processing
- tips:
- process data in the most efficient order. If it takes less time to deduplicate than clean up the data, deduplicate first
- do trial runs of scripts before running on full dataset
- avoid changing data in place
- inspect data
- plot the distribution of tokens, input/output lengths etc
- look for patterns. Manual inspection brings good results
- if there are annotations, annotate yourself and compare
- deduplicate data
- multiple levels:
- whole document duplication
- intra-document duplication: same paragraph appears twice in the document
- cross-document duplication: same quote in multiple documents
- you have to define what duplication means e.g. full match or 80% overlap etc.
- helpful techniques:
- pairwise comparison – similarity score between each pair – expensive approach
- hashing
- dimensionality reduction
- multiple levels:
- clean and filter data
- remove formatting e.g. html or markdown syntax
- remove pii, copyright, toxic data
- manual inspection can help find patterns e.g. data annotation can have worse quality over time due to annotator’s fatigue
- format data
- e.g. make sure to use the right tokenizer
- switching from prompt engineering to finetuning may require changes e.g. fro. X-shots prompt to X examples.
9. Inference optimization
It can happen on: model, hardware and service layer.
Understanding inference optimization
Bottlenecks:
- compute-bound
- memory bandwidth-bound: transferring data from CPU to GPU.
prefill step is compute bound, decode is memory bandwidth-bound. Therefore these 2 steps may run on separate machines.
Types of inference APIs:
- online API – optimized for latency
- you can turn on streaming to reduce time to first token but with that you can’t verify the response before sending to the user
- batch API – optimized for costs
- use cases:
- synthetic data generation
- periodic reporting e.g. summarizing slack messages, sentiment analysis
- onboarding new customers who require processing of documents
- generating personalized recommendations
- use cases:
Inference performance metrics
The key metric is latency. (Response quality is part of the model metrics, not inference service).
For autoregressive generation in the streaming mode it can be broken down:
- Time to first token (TTFT)
- for chatbots it’s expected to be fast, for document summarizing it’s acceptable to be lower
- Time per output token (TPOT)
- doesn’t need to be faster than human reading speed. Fast reader can do 120ms/token or 6-8 tokens/second
- Time between tokens (TBT) and inter-token latency (ITL)
The total latency is TTFT + TPOT x tokens. The same latency can be achieved with different values. Would you rather prefer a first first tokens and wait longer between, or wait more initially but then get fast generation?
You can manipulate by shifting compute resources from decode to prefilling and vice versa
Latency is a distribution so average doesn’t make sense. Rather look at percentiles.
Throughput:
- tokens per second
- completed requests per minute (because one request usually takes more than a second). Good to check how the service deals with concurrency
- goodput – number of requests per second that meet the SLO
- throughput is closely connected to cost
Utilization:
- GPU utilization is not a good metrics because it measures how long the GPU is busy but not if used efficiently
- MFU (Model FLOP/s utilization) and MBU (Model bandwidth utilization) are better
AI accelerators
- CPUs have a few powerful cores, designed for general tasks. GPUs have a lot of small cores to support parallel processing
- accelerators usually are designed for inference
- they can be optimized for different models, architectures, data types
- the less bits used the faster the calculation
- memory hierarchy:
- CPU DRAM
- GPU HBM
- GPU SRAM
- power consumption
- e.g. a single NVIDIA H100 uses yearly 7000 kWh
Inference optimization
- hardware-level
- model-level
- model compression
- quantization
- distillation
- pruning – reducing no of parameters by removing neural network layers. Or finding parameters least useful for predictions and setting them to zero
- speculative decoding
- draft model which is faster but less powerful generates tokens and the target model verifies them (in parallel, because it’s possible for verification). If nothing is good enough the target model produces the output
- inference with reference
- copy parts of the input tokens to the output token. E.g when doing code changes based on existing code
- attention mechanism optimization e.g. windowed attention, improving KV cache size or writing kernels for attention computation
- kernel is a piece of code optimized for specific hardware accelerators
- key techniques: vectorization, parallelization, loop tiling (optimizing data accesing order), operator fusion
- model compression
- service-level
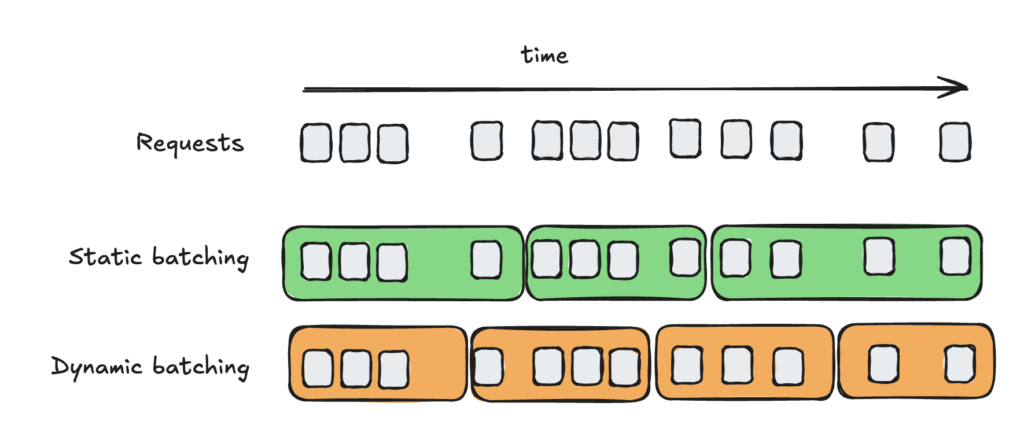
- batching: static (wait for full batch), dynamic (wait for full or fixed window), continuous
- decoupling prefill and decode
- prompt caching
- it may decrease latency but you may need to pay extra for cancer cache memory storage
- parallelism
- replica parallelism – multiple replicas of the model
- pipeline parallelism – rather used for training as it increases throughput, not decreases latency
- context parallelism – split context into multiple parts
- sequence parallelism – if both attention and feedforward needed it can be split into multiple machines
10. AI engineering architecture and user feedback
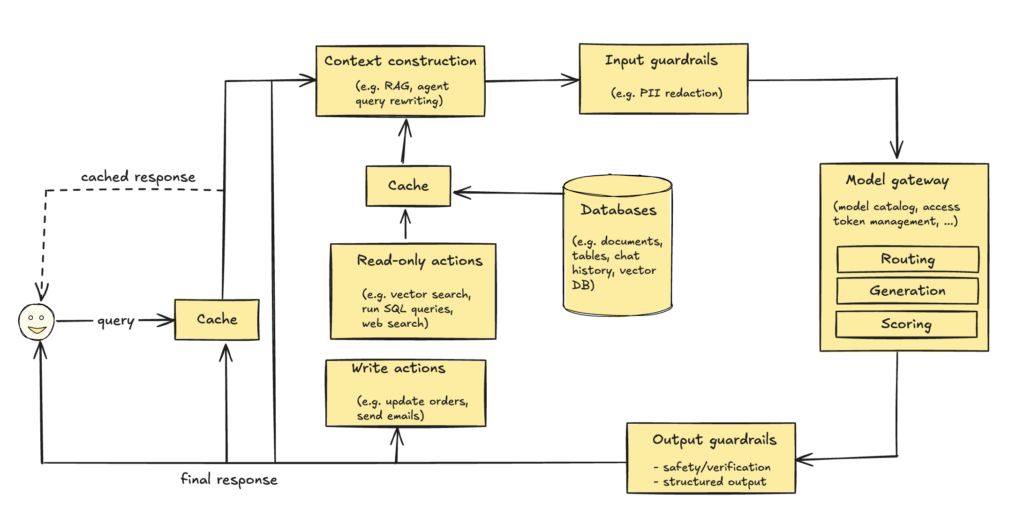
- step 1: enhance context
- step 2: put in guardrails
- input and output
- you may consider transferring users to humans e.g. when the output guardrail detects anger or too many retries
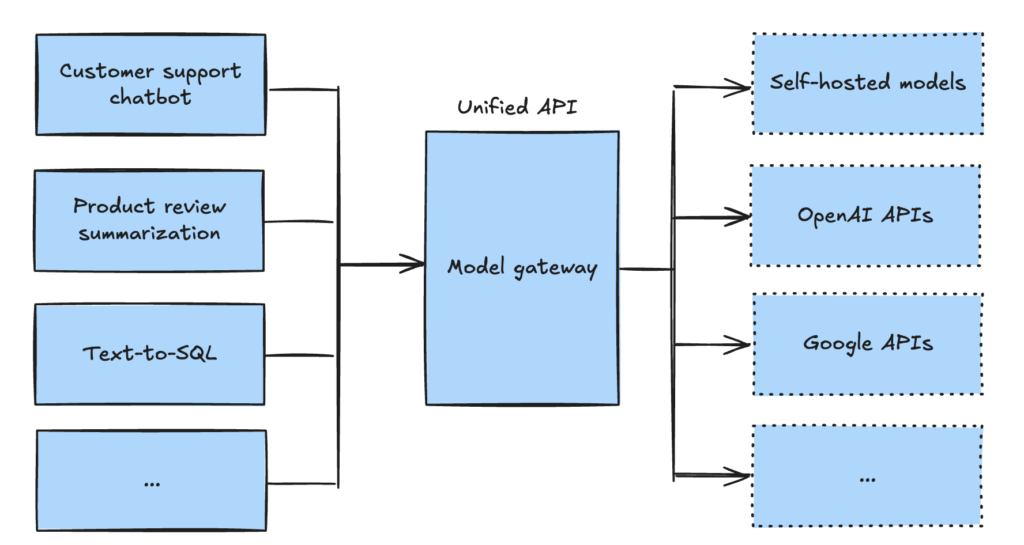
- step 3: add model router and gateway
- router – intent classifier. You can use a cheaper model for that
- gateway – a layer to decide which model to use. Also access control and cost management
- step 4: reduce latency with caches
- exact cache
- semantic cache – requires calculating embedding first to know if it’s semantically the same
- step 5: add agent patterns
Observability and monitoring
- understand failure modes of your system and design metrics that catch that. E.g. metric that helps detect hallucination.
- drift detection – many components can change
- system prompt changes
- user change their behavior (because they learn how to use system efficiently)
- underlying model changes
AI pipeline orchestration
- it can be used to for example redirect the user to human operator when the LLM response evaluation fails
- example tools: LangChain, LlamaIndex, Flowise, Langflow, Haystack
User feedback
- user feedback can serve multiple purposes
- evaluation: monitoring the application, (quality)
- development: train future models or guide the development
- personalization: personalize the application to each user (preference)
- natural language feedback:
- early termination – stopping the response generation, closing the tab
- error correction – “no … I meant”
- complaints
- sentiment analysis (and the change of it during the conversation)
- other types of feedback
- regeneration. Could mean user is not satisified. But can mean user is just curious if another response would be consistent
- conversation length – depends on the use case. For AI companion it may be a sign user is enjoying the conversation. For chatbots focused on productivity it’s aimed to be fast
- dialog diversity
- when the model has low confidence we can ask usere for feedback to increase it
- it’s advised against asking for feedback when something good happens. Users should assume app produces good results by default.
- user feedback will have biases
- leniency bias. E.g. user gives positive feedback to dismiss the window because they know that if asked negatively they would receive follow up questions
- randomness e.g. When shown with 2 responses users may choose 1 randomly not reading the other one.
- position bias – users are more likely to click on the first suggestion
- preference bias / recency bias
- degenerate feedback loop – when user feedback modified model’s behavior – popular video is even more popular because it’s recommended – exposure/popularity bias or filter bubbles
You can find me on goodreads 🙂



