
Context
Imagine a tech startup – a group of young programming enthusiasts that have an idea and great ambitions. Three developers want to deliver the first prototype as quickly as possible. To achieve that they split and each of them works on a different part of the system. Fast-forward 3 years. Our startup turned out to be successful. They found their market fit. The team is no longer three developers – it’s thirty now! Working there slowly becomes frustrating. Every new developer is overwhelmed by a number of topics to digest during onboarding. The company is at the stage when everybody has to know everything in order to progress.
The engineering manager would like to split the engineering department into multiple teams to reduce the cognitive load of the people and make the teams more focused. If we consider Conway’s law, when we have all engineers work as a single team, the system they would produce would resemble the team’s structure – which in this case is a single block. This isn’t good if we want the company to scale.
Inverse Conway Maneuver
Separating engineers into multiple teams having a system that still is a single unit, is not an optimal solution. It would introduce a lot of back and forth communication between teams. There’s a smarter and more proactive solution to that – Inverse Conway Maneuver (Team topologies, 2019). We apply a team structure that with the forces of Conway’s law would eventually shape the system to the expected architecture.
Problem
So the biggest concern with applying the aforementioned technique is that the knowledge the company possesses was generated without these new clear boundaries in mind. This undoubtedly will be a challenging period. Over time, experts in certain topics were born.
- “We need to change something in the payment system.”
- “Ok, let David do it. He knows it best”
And suddenly we have people ending up in teams that don’t focus in these areas they’ve been working so far.
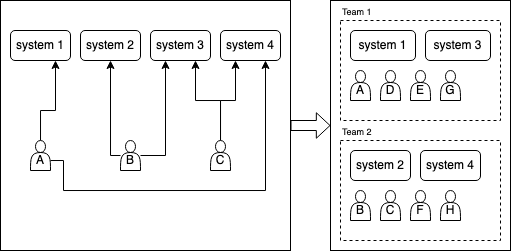
Now, people from team A are going to keep asking an expert from team B over and over again. As a result, an expert from team B is not going to deliver results, and at the same time is going to become frustrated. Ultimately team A will learn everything about their area of expertise, but until they reach this point, an expert from team B may quit. Alternatively, considering an expert is less likely to help, team A does their job with a trial and error approach. They slowly progress, but also leave some mess behind, that only increases complexity of the system, causes frustration, and makes it harder for new joiners to understand the code.
Idea – let’s identify the gaps
So we can assume that ultimately the system is going to adapt to the teams’ shape. We also know that ultimately team members will know their domain. Is there anything we could do better here? Absolutely. We can act proactively – identify the gaps, and reduce them.
We can for example ask current experts to transfer their knowledge into documentation. Or we can organize workshops for given topics.
But how can we identify the gaps?
Solution – the knowledge matrix
We could create a knowledge matrix – put team members in one dimension, areas of knowledge in the other one, and rate each intersection.
A simplified version could look like this:
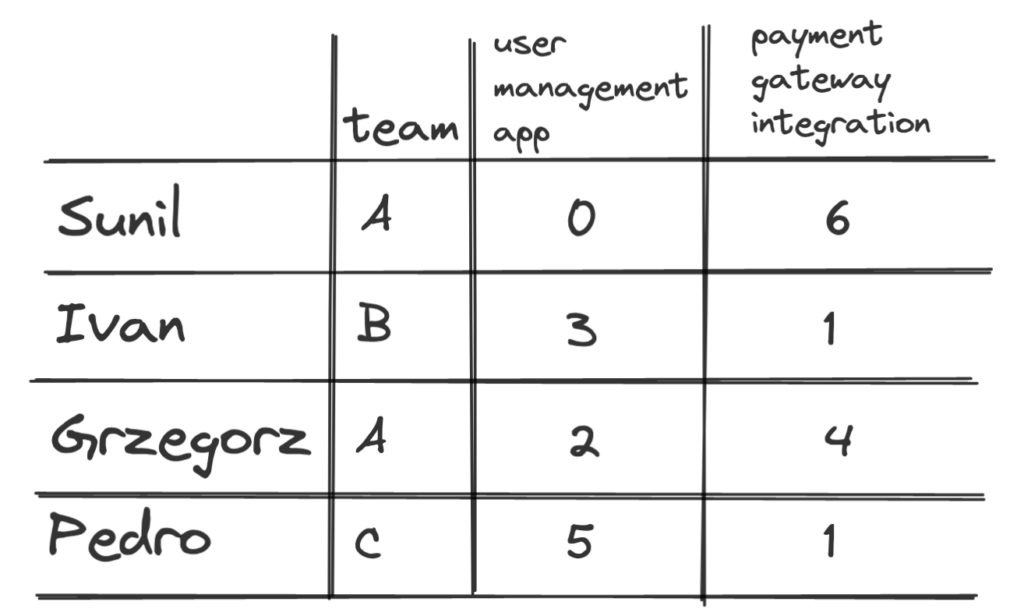
An example rating system could look like following:
- 0 points – I’ve never heard of it / I don’t know the technology behind so I won’t be able to contribute
- 1 point – I don’t know how it works and I don’t know exactly what it is but I know the technology behind it so I would be able to contribute
- 2 points – I know how it works/looks but I don’t know how it’s built / where’s the code
- 3 points – I have seen the code/details, but I don’t feel comfortable with that / I need some guidance
- 4 points – I feel ok with doing stuff on my own but probably it may take some time – I’m still learning this part. I’m able to onboard new people but not very efficiently.
- 5 points – I know it well. I know what to do to achieve my goals. I’m able to onboard new people.
- 6 points – I feel extremely confident about it – I can answer questions/propose solutions. I’m able to onboard new people.
Should we use technical skills?
One question that may come up here is whether we should include technical skills as columns. We could, but it depends on the goal we would like to achieve. If you’re looking for people with certain skills to compose or enhance some teams’ capabilities, that makes sense. But if we’re considering the case described earlier, our goal is to understand where the gaps in domain knowledge are, because we may assume all people have similar technical skills.
How granular should the knowledge areas be?
There’s no easy answer to the question how granular the knowledge areas should be. It all depends on our team. For example, if the team consists of mobile and backend engineers assuming they only know their technology, we can have two items for each domain area – one for the mobile app, one for the backend. E.g. “purchases in the app”, “purchase processing in the backend”. The best idea would be to sit with all the engineers, let them brainstorm and write down all areas they think would be relevant, group them together, and after a couple of iterations we could end up with a reasonable list of topics.
How often should we update it?
The simplest answer to the question how often we should update the knowledge would be “when we need it”. In theory we could ask engineers to fill it in regularly, but what’s the benefit considering the cost? Unless we want to have constant updates on the knowledge distribution there’s no need to put so much focus on it. It may be useful when we’re in the transition period when we’re trying to adapt to the new team layout. It may be also useful when new people join the team, so they can quickly check who knows what. So if there’s not that big rotation in the team, it can also be a good idea to fill it in before the team grows.
What if the company has 1000 engineers?
How should we structure the matrix if the number of engineers is really huge? It doesn’t really matter. We could have a “team”, or “department” property to filter the team members. But if the organization is really big, we could convert our matrix to a different level. Instead of single people we could have whole teams and the areas they work on. But this obviously assumes we’re no longer talking about our thirty-developers startup from the beginning of the article.
Which tools should we use?
To build the matrix we don’t need any sophisticated tools. Excel or Google Sheets are perfect. They let us filter rows, they let us use conditional formatting to highlight low levels of the skills in certain areas, and they are easy to share and update.
Conclusion
If our company reaches a point where there are too many people, more teams need to be introduced. This usually results in incorrect knowledge distribution. According to Conway’s law the system will eventually adapt to the new organization structure. But until this is achieved, people can become frustrated and leave. We can act proactively by identifying gaps and reducing them. A tool that can help us with that task is the team knowledge matrix. A simple table in Excel or Google sheet that helps us show who knows what. Depending on the technical skills of people in the teams, the categories may be different. It’s a good idea to sit down with the engineering team and decide on the knowledge areas together. The matrix itself could be updated on-demand e.g. before new people join the team. The matrix could also be used in larger organizations where whole teams are put instead of single people.
References
- Pais, M., Skelton, M., Team Topologies, (IT Revolution Press, 2019), chapter 1



